AI Voice Cloning
Did you know that AI can now replicate your own voice? Seriously! This voice cloning tool is simply awesome.

Software Engineer @ Facebook
Did you know that AI can now replicate your own voice? Seriously! This voice cloning tool is simply awesome.
In this blog post, I’ll talk about diagonalizability, what it is, and why it may be useful to diagonalize matrices (when they can be) to efficiently compute operations on matrices. I won’t go into detail when a matrix is diagonalizable, but it will be briefly mentioned in an example.
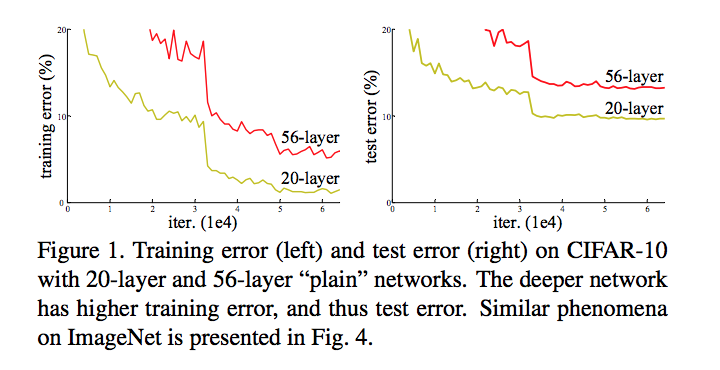
Optimizing deep neural networks has long followed a general tried-and-true template. Generally, we randomly initialize our weights, which can be thought of as randomly picking a place on the “hill” which is the optimization landscape. There are some tricks we can do to achieve better initialization schemes, such as the He or Xavier initialization.
Towards the end of 2017, I started using an iOS app called Moment, which tracks how much time you spent on your phone each day and how many times you pick it up. Through using this application for the year of 2018 and poking around in the app for a way to export my day-by-day data, I was able to obtain a JSON file consisting of my phone usage time and number of pickups for every day of the year.
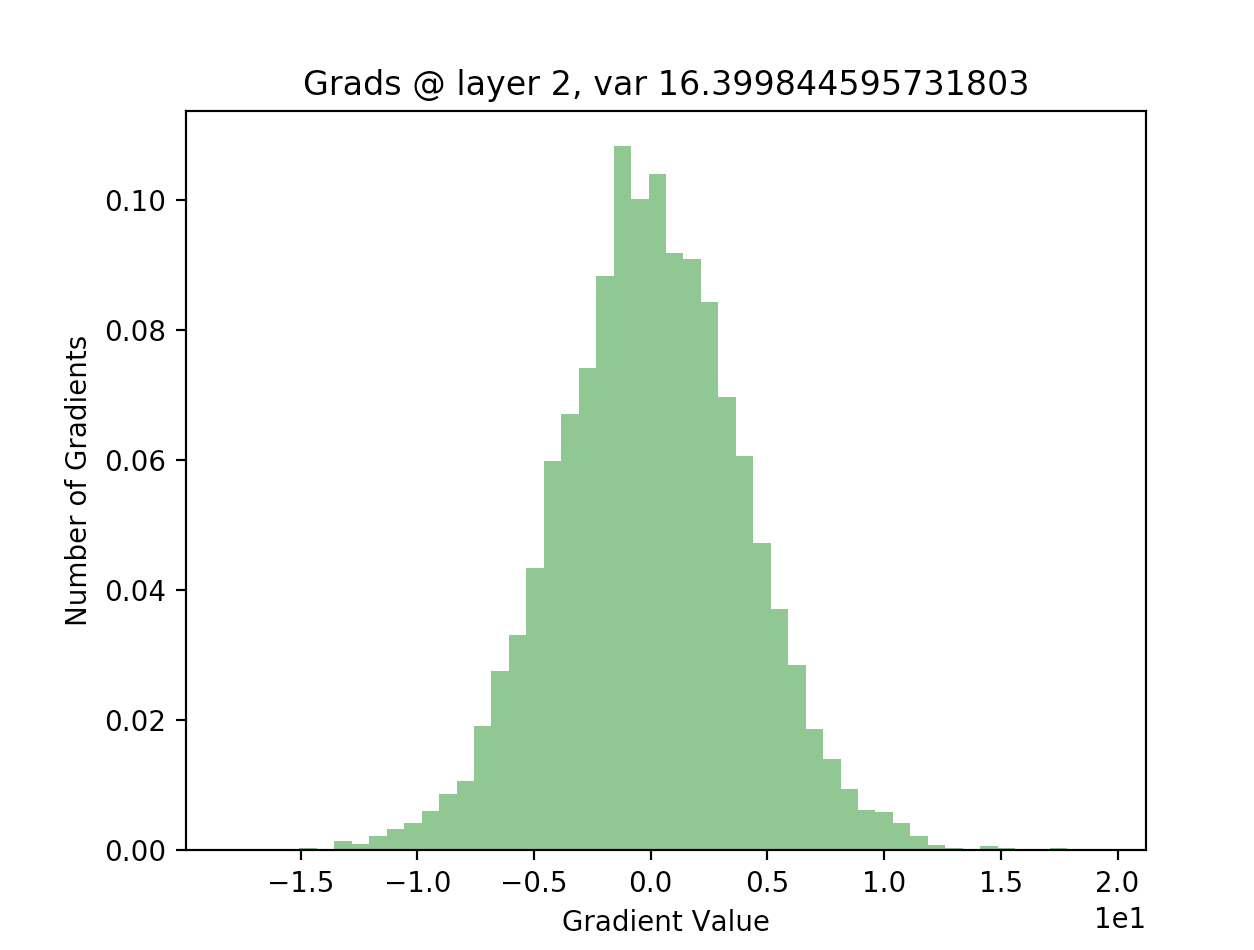
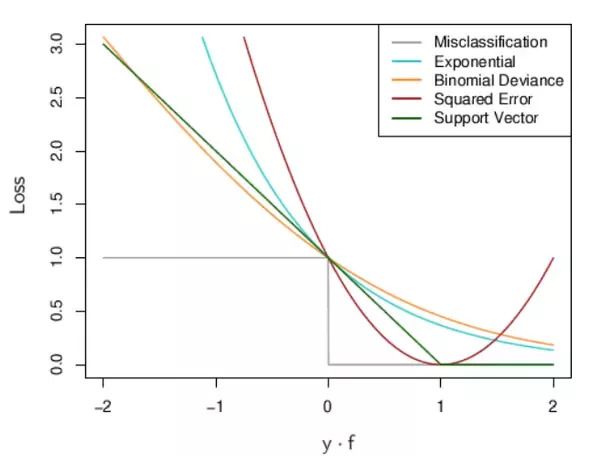
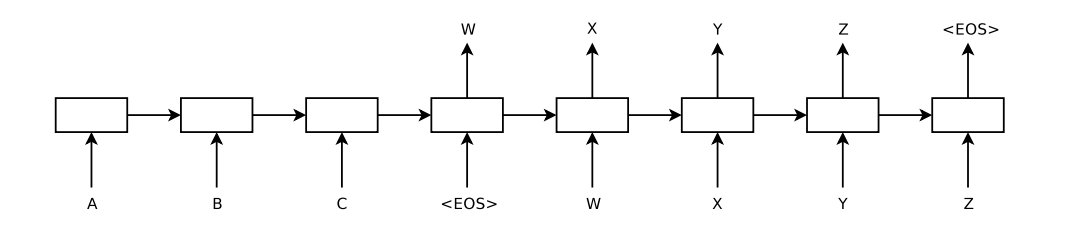
This is a write-up and code tutorial that I wrote for an AI workshop given at UCLA, at which I gave a talk on neural networks and implementing them in Tensorflow. It’s part of a series on machine learning with Tensorflow, and the tutorials for the rest of them are available here.
Over the summer of 2016, I was a software engineering intern at Hudl, a company that builds software to help sports teams play, communicate, improve, and win. This blog posts covers some of the essential takeaways from my internship.
Recently, I spent sometime writing out the code for a neural network in python from scratch, without using any machine learning libraries. It proved to be a pretty enriching experience and taught me a lot about how neural networks work, and what we can do to make them work better. I thought I’d share some of my thoughts in this post.