
Paper Analysis - Sequence to Sequence Learning
Link to paper Link to example implementation
Abstract
-
Traditional DNNs have achieved good performance whenever large labelled training datasets are available, but cannot map sequences to sequences
-
Main approach of the paper is to use a multilayer LSTM to map input sequence to a fixed-length vector, and then another deep LSTM to decode the fixed length vector into a sequence
-
The LSTM model also learned useful phrase & sentence representations that are sensitive to word order and invariant to passive/active voice
-
indicates that the actual structure of the language was mostly captured, the representation of “He ate the cookie” and “the cookie was eaten by him” aren’t too different
-
Reversing word order in source sentence helped because it introduced more short-term dependencies
Introduction
- DNNs are powerful, example: 2 layer neural network of quadratic size can learn to sort n n-bit numbers
- DNNs are only useful for problems who’s inputs and labels can be expressed as fixed-length vectors in some way
- This is limiting, DNNs can’t do many tasks who’s inputs are best represented as sequences such as machine translation, POS tagging, speech recognition
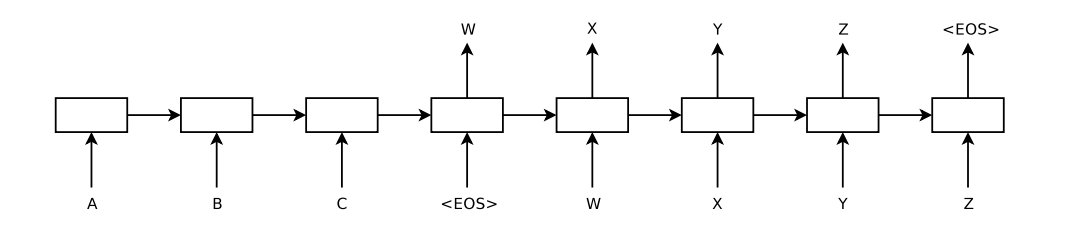
- Main idea: use one LSTM to read the input sequence (of variable length) one time step at a time, and map this to a fixed-length vector. Then a second LSTM takes this fixed-length vector as an input and produces an output sequence
- The second LSTM is basically an RNN language model that is conditioned on the encoded representation
- The researchers trained an ensemble of 5 deep LSTMs (each with 384 million parameters) and used a beam search decoder to achieve state of the art performance on the WMT english to french translation task
- Reversing the words in the source sentence helped train the LSTMs a lot, because this introduced many more short term dependencies to make it easier to train the LSTM with SGD
Model
-
RNN inputs: sequence \(x_1 … x_T\) as inputs, computes a sequence of outputs \(y_1 … y_T\)
-
At each timestep, RNN computes a hidden state \(h_t\) and an output \(y_t\). We can think of the hidden state as encapsulating the information encountered at previous timesteps
- \[h_t = tanh(W_{hx}x_t + W_{hh}h_{t-1})\]
- \[y_t = W_{hy}h_t\]
-
This is for a “single-layer” RNN that does not have layers of hidden states. If there are multiple layers of hidden states, then instead of \(x_t\) as the input into a later hidden layer, the input is the \(h_t\) at the previous layer, same timestep
-
For general/variable-length sequence to sequence learning, the general idea is to map the input sequence to a fixed-length vector using one RNN and then map the fixed-length vector to the target sequence with another RNN
-
However, in practice RNNs aren’t very good with learning longer-term dependencies. LSTMs have been shown to do much better at learning longer-term dependencies because they don’t fall victim to the vanishing gradient problem like traditional RNN cells do
-
Goal of the LSTM is to estimate the following conditional probability:
- \(p(y_{1}, … y_{T'} \vert x_{1} … x_{T})\) , where the length of the 2 sequences differ from each other
- The LSTM does this by computing a fixed-dimensional representation \(v\) after observing the input sequence \(x_1 … x_T\)
- Then, conditioned on this \(v\), we can produce the output sequence via the following formulation:
- \[p(y_1 | x_1 … x_T) = p(y_1 | v)\]
- \[P(y_1, y_2 | x_1 … x_T) = p(y_2 | v, y_1) p(y_1 | v)\]
- i.e., at each time step the the \(i\)th output is conditioned on the fixed length vector \(v\) and the previous outputs, if any
- In general, \(P(y_1, y_2 … y_{T'} \vert x_1, … x_T) = \prod_{t = 1}^{T'} p(y_t \vert v, y_1… y_{T'-1})\)
- Each of these distributions are represented with a softmax over the vocabulary
- 2 different LSTMs are used since this doesn’t increase the number of model parameters by much and makes it easier to train the LSTM on multiple language pairs
- A deep LSTM was used with four layers; this was found to significantly outperform shallow LSTMs
- Reversed order of words in input sequences was found to help a lot
- The dataset had 12m sentences with 348m french words and 304m english words
Training
- Model was trained to maximize probability of producing a correct translation given a source sentence:
- \[\frac{1}{N} \sum_{i=1}^{N} \log p(T_i | S_i)\]
- Translations are produced by finding the most likely translation given by the LSTM: \(T* = argmax_T p(T \vert S)\)
- Beam search used to find the most likely translations. At each time, we maintain a list of partial hypotheses and then extend each partial hypothesis with every word in the vocabulary. Then we discard all but \(B\) of the most likely hypotheses (where the likelihood is given by the model’s log probability).
- A hypothesis is finished once the end-of-sentence tag
is emitted - As discussed, reversing the words in the source sentences helps the translation task a lot
- An intuitive explanation for this is by reversing the source sentence, the average distance between corresponding words decreases so there is less of an overall time lag
- Therefore, backpropagation has an easier time communicating between the source sentence and the target sentence.
- Ex: “I like to eat the apples” and “Me gusta comer las manzanitas” vs “Apples the eat to like I” and “Me gusta comer las manzanitas”, the second pair has more words closer to the corresponding word in the translated sentence
- A deep LSTM with 4 layers and 1000 cells at each layer was used. 100 dimensional word embeddings
- Initialization was uniform random between -0.08 and 0.08
- SGD without momentum with lr = 0.7, and then the learning rate was halved from epochs 5 to 7.5
- batch size = 128
- To avoid exploding gradients, the researchers enforced a hard cap on the norm of the gradients and the gradiewnts weres scaled down when the norm exceeded a threshold
- Each layer was trained on a different GPU and communicated its activations when it was one. Spent about 10 days training
Results
-
The model achieved state of the art accuracy on english to french translation tasks
-
The fixed length vectors learned were pretty meaningful, in that they were sensitive to order of the words (i.e. John admires Mary was further away from Mary admires John, but Mary admires John and Mary respects John were relatively close together)
-
Other approaches included using convolutional networks to map sentences to fixed length vectors, using attention mechanisms to overcome issues with long sentence translation, or taking phrase-based approaches to achieve smoother translations